過去のホームページの掲載情報を復活する方法
Contents
過去のホームページの掲載情報を復活する方法
「ウェブサイトの過去のページを見たい」とか、「消してしまったホームページのデータを取り戻したい」といった経験はありませんか?
更新後、サーバーからは失われてしまった過去のデータも、もしかすると閲覧したり取り戻したりすることができるかもしれません。今回は、データがサーバーに残されていなくても、過去のページを見る3つの方法をご紹介します。
Google検索でキャッシュを見る
Googleは、ウェブサイトを巡回して、そのデータを同社のサーバーに一時的に保存しています。これを「キャッシュ」と言います。ウェブサイトのデータが消されていても、Googleには巡回当時のデータが残っている可能性があるのです。
キャッシュの見かた
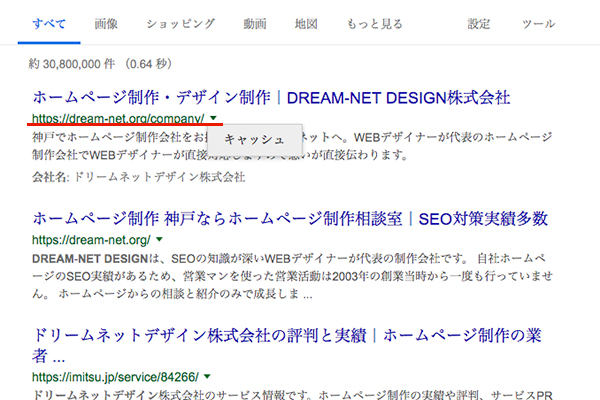
過去のページが見たいサイトを検索し、表示結果のURLの右端にある▼をクリック。
表示された「キャッシュ」をクリックすると、前回クロールした時の情報を見ることができます。
ただし、このデータは前回の巡回時のものですから、それ以前のデータを表示させることはできません。ほとんどは、当日か前日で上書きされてしまいます。
Wayback Machineを使う
ウェブ情報をはじめ、世界中のさまざまなデジタル情報をアーカイブしているアメリカの非営利団体Internet Archive。この団体が運営しているのが「Wayback Machine(https://archive.org/web/)」です。
Wayback Machineは、アーカイブにアクセスし、指定した日付の時点のウェブサイトを表示させることができます。
Wayback Machineの使い方
フォームにURLを入力して「BROWSE HISTORY」をクリックします。すると、閲覧可能な過去の年月が表示されます。
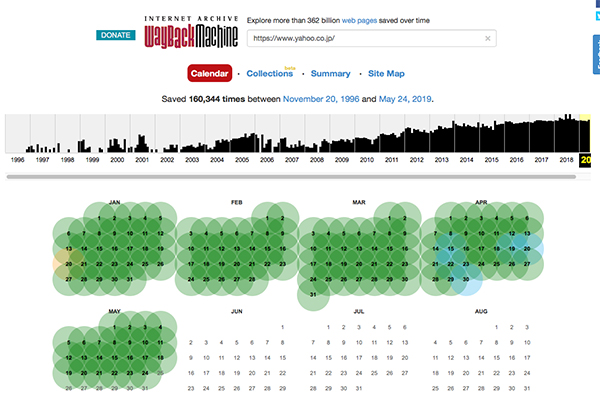
見たい年月をクリックすると、下にカレンダーが表示されます。
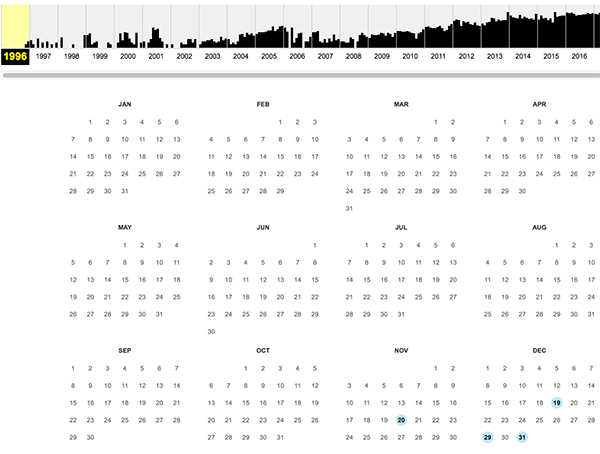
これは、Yahoo!Japanのアーカイブを示すカレンダー。青くハイライトされている日付はデータが保存されているため、見ることができます。
もっとも古いデータは、1996年11月20日でした。
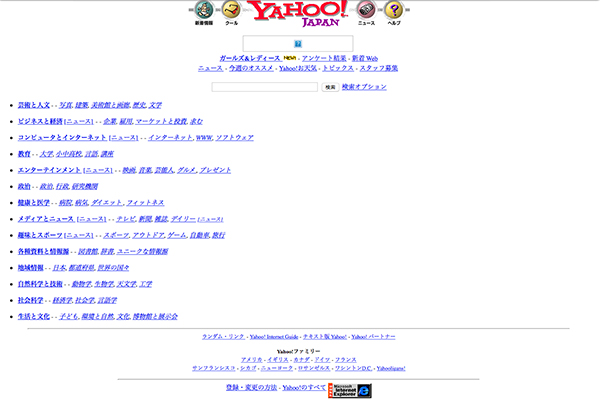
カレンダーの日付をクリックすると、当時のサイトがそのままの姿で表示されます。
Wayback Machineのすごいところは、サイトを丸ごとアーカイブしているので、同一サイト内のページであればリンクを辿って別のページを見ることもできるところ。画像や動画などはリンク切れになっている場合もありますが、それ以外はほぼ当時のそのままの形で閲覧することができます。
ただし、アーカイブされるタイミングはサイトによってバラバラです。更新頻度が高いサイトはアーカイブの周期が短く、更新頻度が低いサイトは周期が長いという傾向はあるものの、サイトが更新されるごとに保存されていくわけではないので、お目当てのページが見つからない場合もあります。
また、robots.txtの設定によってWayback Machineのクロールを拒否することができるので、サイト運営者が拒否している場合もアーカイブされません。
魚拓サービスを利用する
「魚拓」は本来、魚の姿を紙に転写することを言います。ウェブでも同様に、サイトのキャッシュを保存しておくことを「魚拓をとる」と言います。この魚拓を保存してくれるサービスが、「ウェブ魚拓(https://megalodon.jp/)」。
ただし、Wayback Machineのように世界中のサイトを自動でクロールしているわけではなく、データを保存しているのは個人。ですから、求めるページが必ずしも保存されているとはかぎりません。しかし、話題になったページは誰かが保存して残っている可能性が高いです。

こちらがウェブ魚拓のサイト。
URLでもフリーワードでも検索できる点が便利です。
検索すると、保存された魚拓ページが一覧で表示され、閲覧することができます。
キャッシュを禁止しているサイトは保存できず、また削除されることも多いのが難点です。
魚拓サービスは、ウェブ魚拓以外にもいくつかあります。
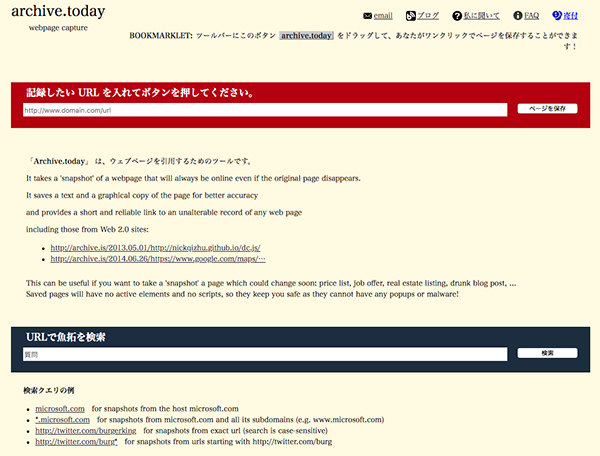
・archive.is(http://archive.is/)
URLで魚拓を検索できます。ウェブ魚拓とも連携しています。
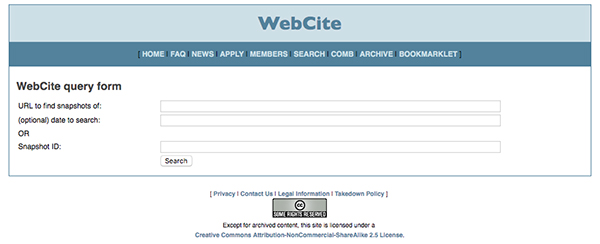
・Webcite(http://www.webcitation.org/query)
もともとは、学術論文用に利用されているアーカイブサービス。サイト自体は英語ですが、日本のウェブサイトも保存されています。
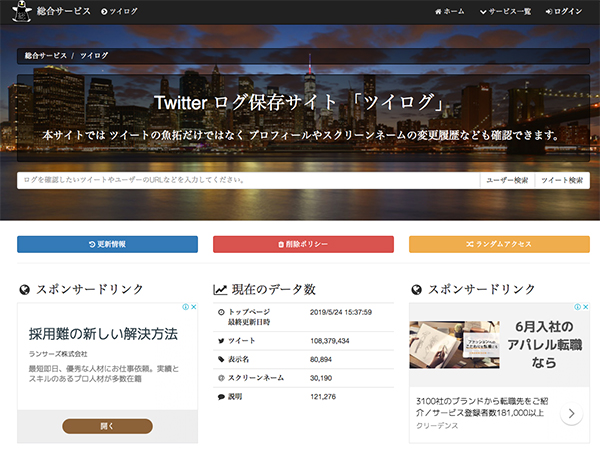
・ツイログ(https://xn--eckyazdvi.xn--vcki1fxh883oon2c.com/)
Twitterのツイートを引用するためのツールで、Twitterのアカウントを持っていなくても利用することができます。非公開のアカウントのツイートを引用することはできません。
・WARP(http://warp.da.ndl.go.jp/)
国立国会図書館が運営するインターネット資料収集保存事業サイト。保存されているサイトは、国の機関や自治体、法人、大学、政党などが中心です。
消えてしまった過去のウェブサイトを閲覧する3つの方法をご紹介しました。
「更新されてしまったから、もう見られないんだ」と諦めず、ウェブサイトの種類や公開日によって使い分けながら、ぜひ試してみてください。